
Ever wished ChatGPT could run entirely on your computer without internet, subscriptions, or data leaks? That’s no longer a fantasy. Thanks to tools like LM Studio, Ollama, and GPT4All, you can now run powerful AI models (known as LLMs or large language models) right on your PC or Mac.
In this guide, I’ll walk you through how local LLMs work, how to set them up, and how they’re changing the game for developers, writers, researchers, and AI enthusiasts.
I’ve personally tested these tools, tinkered with models on a MacBook Air, and experimented with offline chat, code generation, and even Shakespearean storytelling. Running an LLM locally isn’t just possible, it’s surprisingly fun!
Why Run LLMs Locally?
Let’s begin with the big question, “why bother running LLM locally when tools like ChatGPT are just a click away?” Turns out, there are some great reasons:
- Privacy and Control
When you run an LLM on your own machine, your prompts, data, and documents never leave your desk. That’s a big deal for:- Lawyers handling confidential cases
- Developers reviewing proprietary code
- Healthcare professionals writing reports
- Journalists or writers working on sensitive material
- No cloud, no risk of data logging
“Running an LLM locally keeps sensitive data entirely under your control.” — Boston Institute of Analytics
- No Internet? No Problem
Whether you’re traveling, working from a remote area, or just want to stay offline, local models let you chat with AI even without Wi-Fi. Responses are fast, because they don’t wait on cloud servers. - No Cost per Prompt
Cloud-based tools charge per token or monthly. Local tools? Zero cost per query after download. That’s huge for students, hobbyists, and teams experimenting with prompts daily. - Customization and Fine-Tuning
You can tweak local models. Some allow you to fine-tune on your own data (for coding, documentation, or FAQs). Try that with a closed API! - Resilience to Outages
During a recent ChatGPT outage, I was mid-way through writing code. My locally running LLM in LM Studio didn’t skip a beat. That alone made the setup worthwhile.
Local LLMs Has Limits
Running LLMs locally isn’t always simple. Powerful models need serious hardware. Some laptops can only handle small models, and even those can be slow without enough memory. If your computer is older or lacks a good graphics card, you might be limited to basic conversations or short writing tasks. Local models also aren’t as smart as the latest cloud versions, so don’t expect perfect answers every time. But with the right expectations and the right setup local AI is still incredibly useful.
Most laptops can only handle smaller models (3B to 7B), and high-end models like LLaMA 30B or Mixtral 46B need serious horsepower, often with 24GB+ VRAM. Without it, you’ll hit errors, experience slow response times, or find that the model won’t load at all. It’s still early days for local AI, and while it’s getting easier, so START SMALL!
What is LM Studio?
LM Studio is a free, easy-to-use app that lets you:
- Download and manage open-source LLMs
- Run them entirely offline
- Chat through a simple GUI (no coding needed)
It works on macOS (including M1/M2/M3), Windows, and Linux
What makes LM Studio stand out:
- Built-in model catalog (connected to Hugging Face)
- Real-time chat interface
- Apple MLX and llama.cpp backends for optimized performance
- No data leaves your machine
- API endpoints for external tools (e.g. VS Code, browser extensions)
If ChatGPT had an offline twin, LM Studio would be it.
What You Need to Run LLMs Locally?
Minimum System Requirements
- CPU: Any 64-bit processor with AVX2 support (most systems after 2015)
- RAM: Minimum 8GB (better with 16GB or more)
- Disk Space: 10–20GB free per model
- GPU (optional): NVIDIA 3060 or better, or Apple M1 and above with unified memory
- OS: Windows 10+, macOS 12+, or Linux (Ubuntu preferred)
Ideal Setups
| Setup | Specs | Models You Can Run |
|---|---|---|
| Entry-Level | 8–16GB RAM, no GPU | Phi-3 Mini, TinyLlama 1B–3B, 4-bit Mistral 7B |
| Mid-Range | 16–32GB RAM, mid-range GPU | Mixtral 7B, LLaMA 13B, CodeLlama |
| High-End | 32GB+ RAM, RTX 3090/4090 GPU | Mixtral 8x7B, LLaMA 30B+, DeepSeek |
Note on Apple Silicon
Apple M1/M2/M3 chips use unified memory and MLX backend. That means even without a discrete GPU, you can run 7B–13B models quite efficiently.
Don’t Have the Specs?
No problem! Use smaller models (Phi, TinyLlama), or configure LM Studio to forward queries to OpenAI or Claude APIs when needed.
Getting Started with LM Studio to run LLMs Locally
- Visit lmstudio.ai and download the app for your OS
- Install and launch the application
- Click on the “Models” tab to browse and download a model
- Once the model is downloaded, click “Chat” and start typing!
Suggested Starter Models
- Microsoft Phi-3 Mini – Lightweight and fast for general reasoning tasks
- DeepSeek 7B – Balanced performance for code, writing, and Q&A
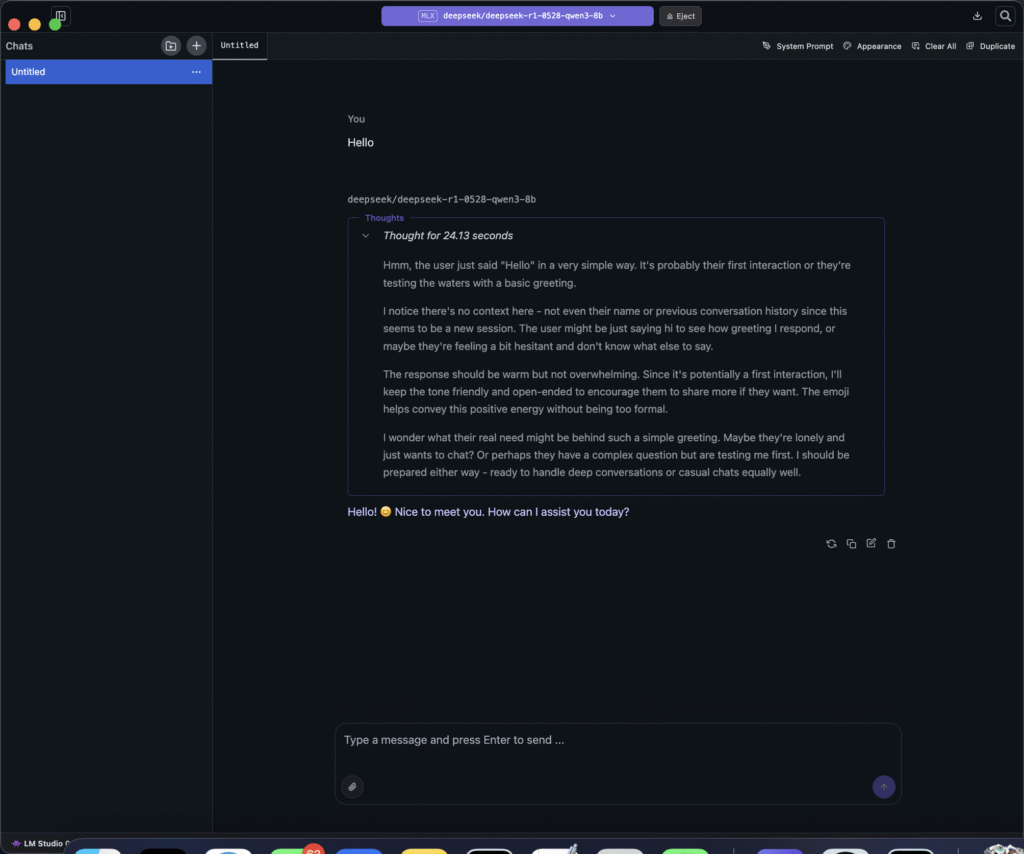
Here is an example using deepseek/deepseek-r1-0528-qwen3-8b with a simple prompt ‘Hello’
Helpful Tips for Better Use of Local LLMs
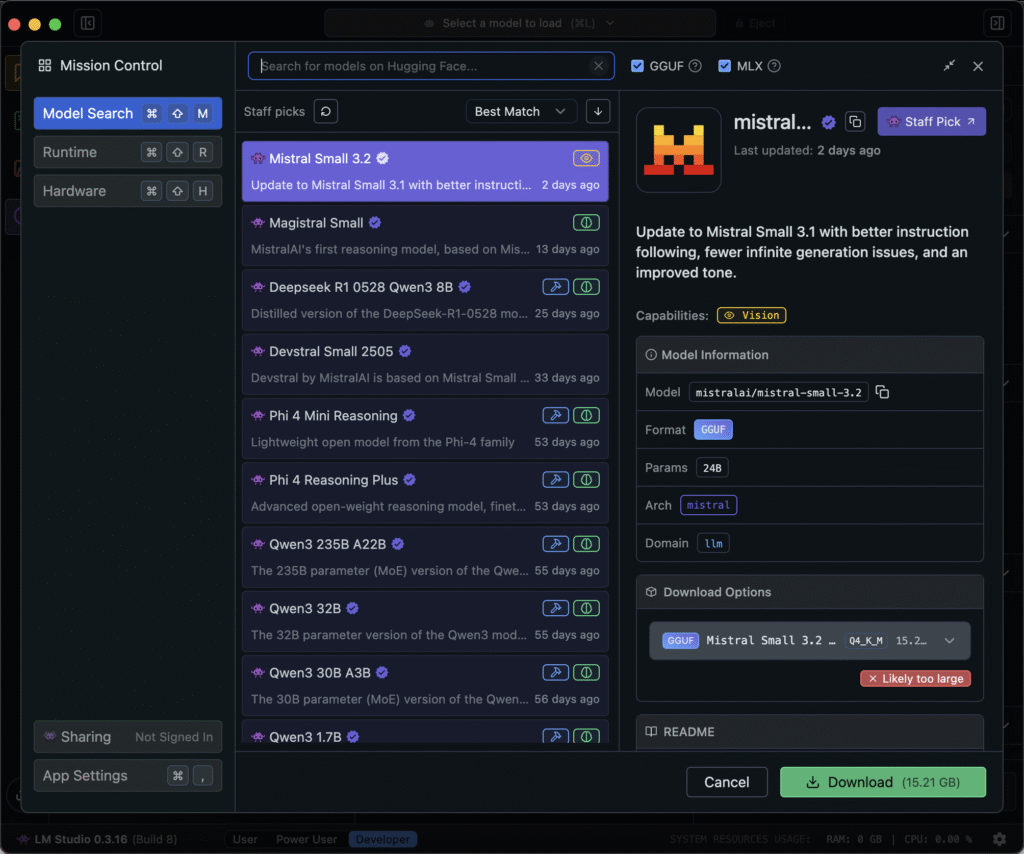
Want to try new models? Just use the search bar in the Models tab to explore community uploads and official releases. Many staff picks are high-quality and pre-tested for LM Studio. You can install them with a single click and start chatting instantly.
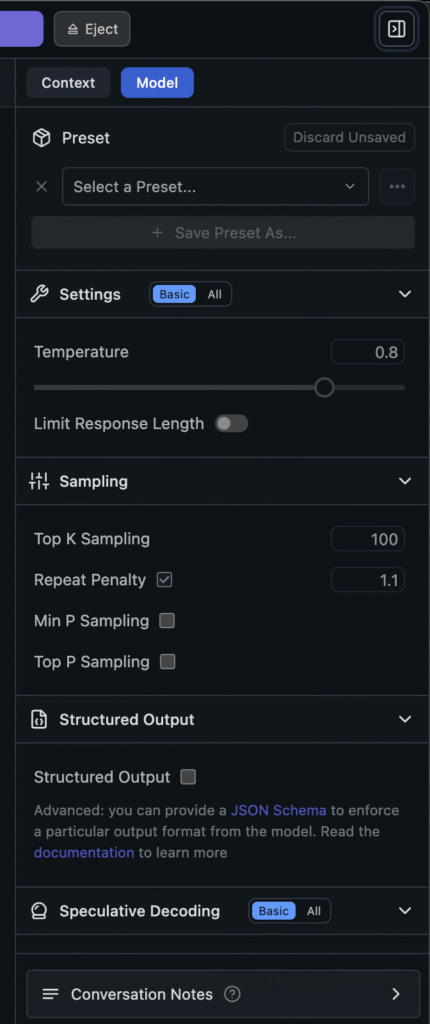
LM Studio includes a powerful Developer Mode that lets you adjust how your model responds. You can tweak settings like temperature (how creative the output is), top-k sampling, context length, and max tokens. For example, when using DeepSeek, I found that lowering the temperature to 0.4 made it better at summarizing reports concisely. Here are the sample settings of Deepseek model on LM Studio running locally
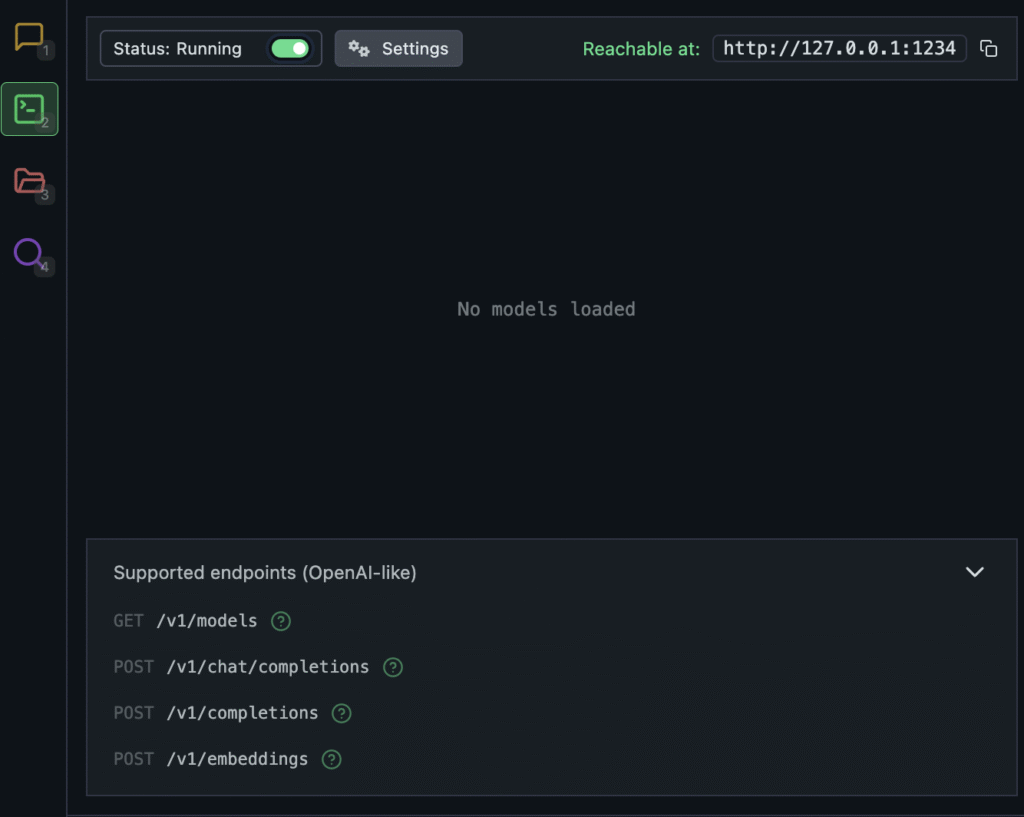
If you’re building other tools or want to access your LLM remotely, LM Studio can act as a local server. Enable the API server from the settings menu and call it from browser extensions or local scripts. It’s perfect for developers integrating AI into apps, tools, or notebooks. Simply switch on the server and start using the API. There is an extensive documentation available too.
Use Cases to Explore Further
- Code Assistant: Use models like DeepSeek or CodeLlama to generate functions, debug logic, or refactor code locally.
- Content Writing: Draft blogs, emails, or social posts using Phi-3 or Mistral.
- Education: Ask for simplified explanations, math steps, or create flashcards.
- PDF Chat: Upload research papers or manuals and ask questions inside LM Studio.
- Brainstorming: Use local LLMs to generate names, ideas, and outlines without limits.
- Offline Usage: Take your LLM on a plane or remote worksite and stay productive.
Why Local LLMs Are Worth Exploring
Running large language models locally may feel like stepping into the future but it’s already here and more accessible than ever. With tools like LM Studio, you can now explore the power of AI without being tethered to the cloud, subscription fees, or internet outages. You stay in control of your data, your tools, and your creativity.
Sure, it’s not all plug-and-play. You might hit hardware limits or struggle to pick the right model at first. But the freedom, privacy, and customizability of local AI more than make up for the learning curve. Whether you’re a developer looking to streamline your workflow, a writer wanting fresh ideas, or just someone curious about how AI works, this setup gives you hands-on experience that no web interface can match.
Local LLMs are not just for tinkerers anymore
So if you’ve ever wondered, “What if I could have ChatGPT on my own laptop?” you now have the tools and knowledge to make it happen. Download LM Studio, pick a model like Phi-3 Mini or DeepSeek 7B, and start experimenting today. Your private, offline, no limits AI journey begins with one simple click.